火车采集器虽然能够采集到url,但如果我们内容中想要引用这个url怎么搞呢?
利用火车头采集获取当前网址url参数可以从URL里截取有用的信息发布到自己的网站上去。接下来就教大家如何获取:
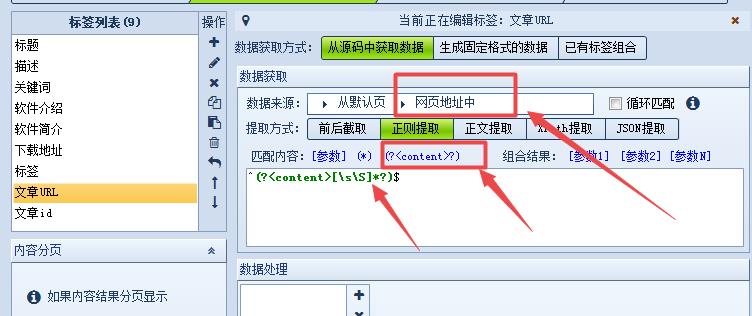
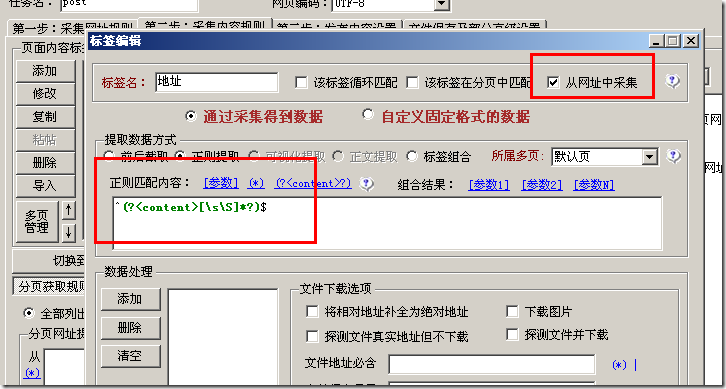
火车头采集器采集网址中url的参数数据。需要用到正则表达式:^(?[\s\S]*?)$
我们在火车采集器中添加标签,然后在数据来源中选择从“网页地址中”,提取方式选择“正则提取”。
点击“(?<content>?)”,下面内容框会出现“(?<content>[\s\S]*?)”,在这串字符前后分别加上一个字符就ok了。变成“^(?<content>[\s\S]*?)$”
Content 代表内容
? 表示匹配0次或者1次
\s 匹配所有空白字符,包括空格、换行、tab缩进等所有的空白
\S 与\s刚好相反,匹配所有非空白字符
* 修饰匹配次数为 0 次或任意次
[ ] 这个符号,表示在它里面包含的单个字符不限顺序的出现
在正则表达式中,美元符号$用于匹配一行的结尾,比如"abc$“表示的是以abc结尾的行,”^$"表示的是空行。^符号是界定符,规定匹配以^后面开头的字符串
如果你想把采集页地址保存到本地文件可以直接使用[标签:PageUrl] 这个就会把网址输出。
上面演示的是火车头V9开心版高铁采集器的设置,火车采集器V7.6也是一样的道理。下面是火车采集器V7.6的设置方法:



评论