火车头采集器的网址采集规则就不多说了,比较简单,最近有朋友问我如何用火车头采集器批量采集下载站的下载文件资源。这里给大家说一下火车头采集器下载文件的采集和设置。
这里就不说具体网站了,只是说一下火车头采集器采集文件的具体配置该如何设置,具体操作主要是在“内容采集规则”里面进行设置。
举个例子:如果对方是帝国cms系统,下载地址如下:
<div class="down_b"> <a href="../doaction.php?enews=DownSoft&classid=37&id=789&pathid=0&pass=833f776ccb5a65c55b777aa5c08ba28b&p=::::::"> 下载地址1</a> </div>
那么真实的下载地址一般是:
https://www.xxxx.com/e/DownSys/doaction.php?enews=DownSoft&classid=37&id=789&pathid=0&pass=833f776ccb5a65c55b777aa5c08ba28b&p=::::::
设置好左侧的“标签”,然后按照下图进行设置
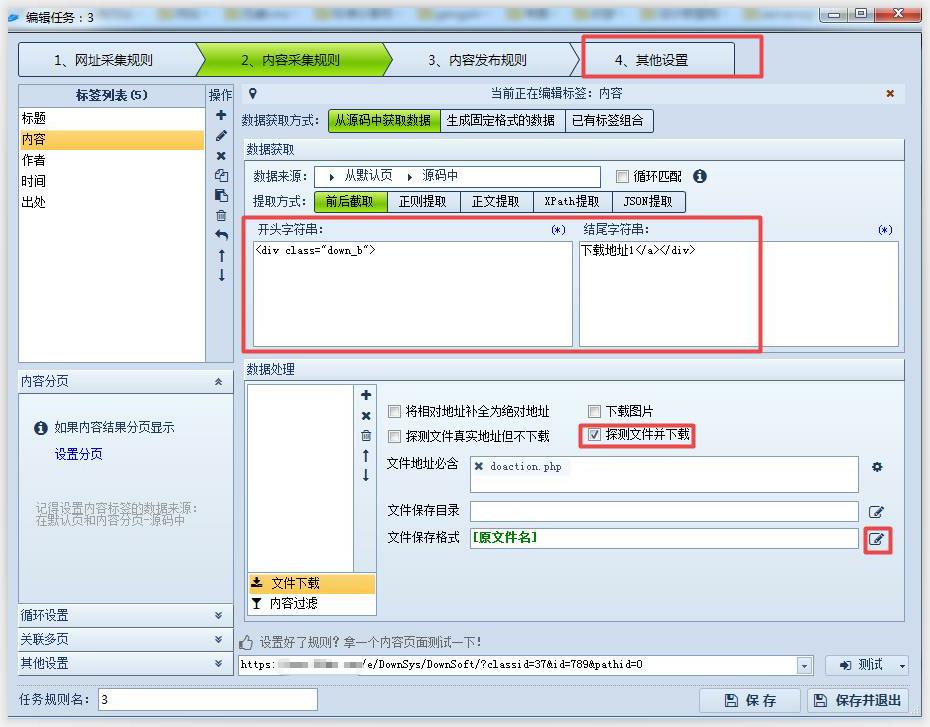
采集规则设置时,需要注意以下设置:
1、数据获取方式为“从源码中获取数据”,提取方式为“前后截取”,开头字符串和结尾字符串在前面代码里面找到特征代码(见上图);
2、选择“文件下载”,勾选“探测文件并下载”;
3、“文件地址必须包含”,这里是为了防止探测到其他下载链接,所以我们最好还是填一下下载地址练的特征字符,我这里写的是doaction.php;
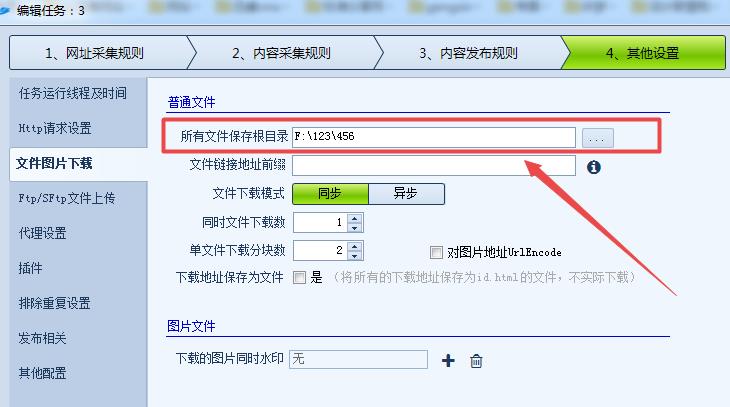
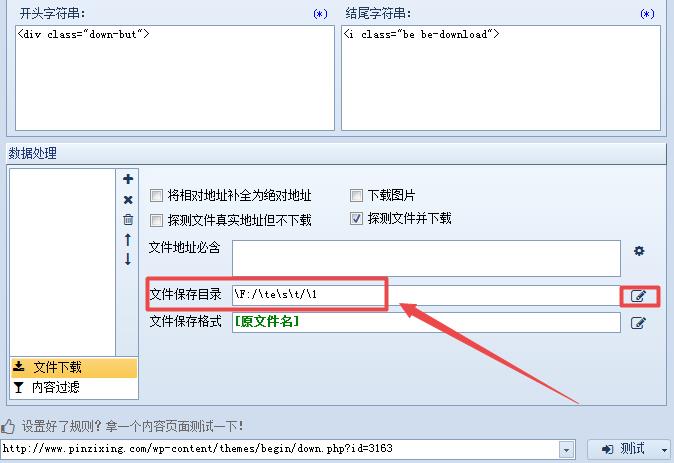
4、文件保存目录如果在这里填写的话涉及到正则表达式比较麻烦,因为涉及到反斜杠转义符,可以参考火车头采集器文件保存目录详解,文件保存目录如何填写这篇文章的具体说明。
我们这里留空就好,在“其他设置”》“文件图片下载”里面设置文件下载目录也是一样的效果;
5、“文件保存格式”,就是下载以后的文件名规则,这里点击后面的小铅笔有默认的几种保存格式,可以以其中一种或者几种格式进行组合。也可以将我们自定义的标签作为文件名进行保存。
以上就是火车头采集器文件下载采集的设置方法。

评论