我们以前介绍过用火车头批量采集下载文件的教程(火车头采集器文件批量下载如何采集?文件下载采集设置)。
那么如果用火车头采集器不能进行文件批量下载的网页,应该怎么办呢?
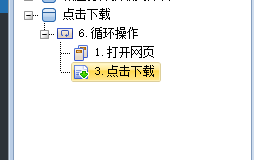
首先新建一个“点击下载”的浏览器脚本,然后进行如下操作:
1、添加一个逻辑运算,选择“循环”;
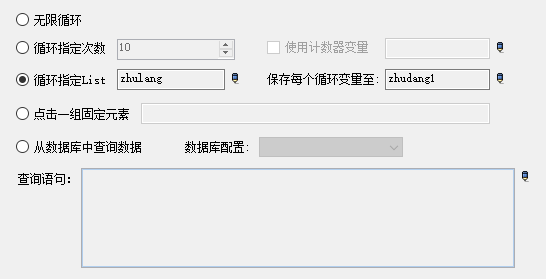
我们新建两个变量,一个list和一个文本变量,循环指定list变量,并保存每个list变量至新的文本变量。
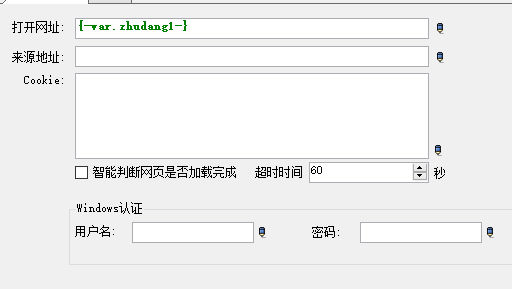
2、添加一个浏览器操作,选择“打开网页”;
设置打开网址,选择变量。
3、添加一个文件下载,选择“点击下载”。
这里设置一下Xpath的提取格式,文件保存目录、文件保存格式和“保存文件路径至”,然后保存。



评论