火车浏览器可以进行浏览器上面的自动化操作,功能非常强大。
品自行一般用火车头采集器进行采集网页上的文章、图片和文件。
但如果对方对火车头采集器进行了限制,我们可以转而用火车浏览器进行采集。最近品自行用火车头采集器采集目标下载站上面的文件时就发现,最多只能采集两三个文件就采集不了了,同时浏览器打开目标网站也无法打开,于是转而用火车浏览器来解决这个问题。
主要是用到火车浏览器的“http下载”,在火车浏览器左侧,右键“文件下载”》“Http下载”。
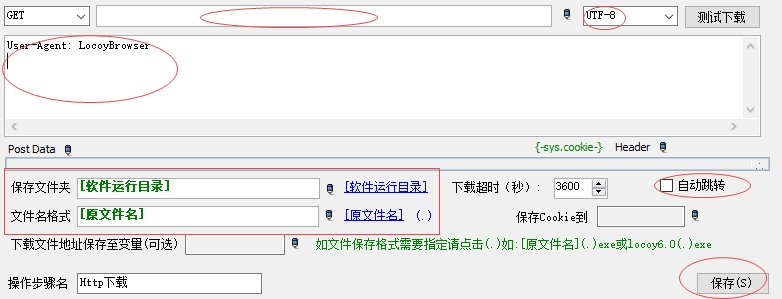
对于下载文件来说,用火车浏览器的http下载是比较好用的,主要设置以下几个参数:
1、获取方式:选择“GET”;
2、下载地址:这里一般也是写在变量里面,在上一步可以通过“取值”获取下载地址到变量,这里直接引用变量即可;
3、编码:根据目标网页的编码进行选择,一般国内要么是GBK或者UTF-8;
4、保存文件夹:可以设置为火车采集器软件运行目录“[软件运行目录]”,或者填写类似这样的目录“F:\abc\3\”;
5、文件名格式:不修改文件名的话就直接填写“[原文件名]”,这里可以通过火车浏览器在浏览器上面取值,比如文件名如果要设置为网页标题,这里就要在前面加一个“取值”的步骤,如果将获取的值写入名为biaoti的变量,这里可以填写“{-var.biaoti-}”;
6、自动跳转:如果真实下载地址是需要跳转获得的,请勾选,如果不用跳转则不用勾选。
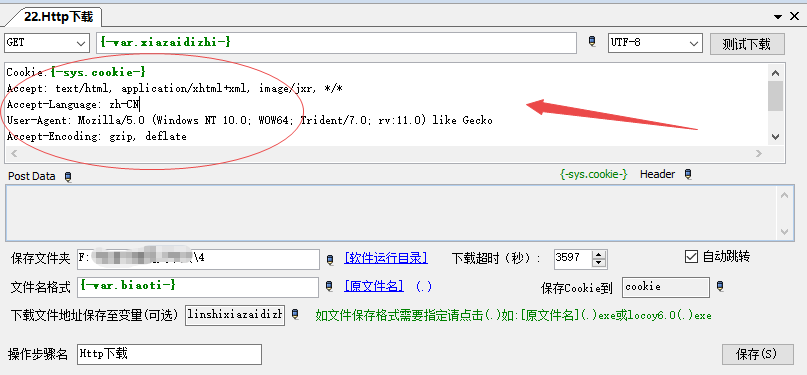
最重要的设置其实是头部信息的设置,需要填写在上图所示的大块空白区域,对于这里的信息我们需要采用Fiddler这款软件来获取,获取头部信息以后即可粘贴到下图指定区域:
全部设置完毕,一定要记得保存方可生效。


评论